
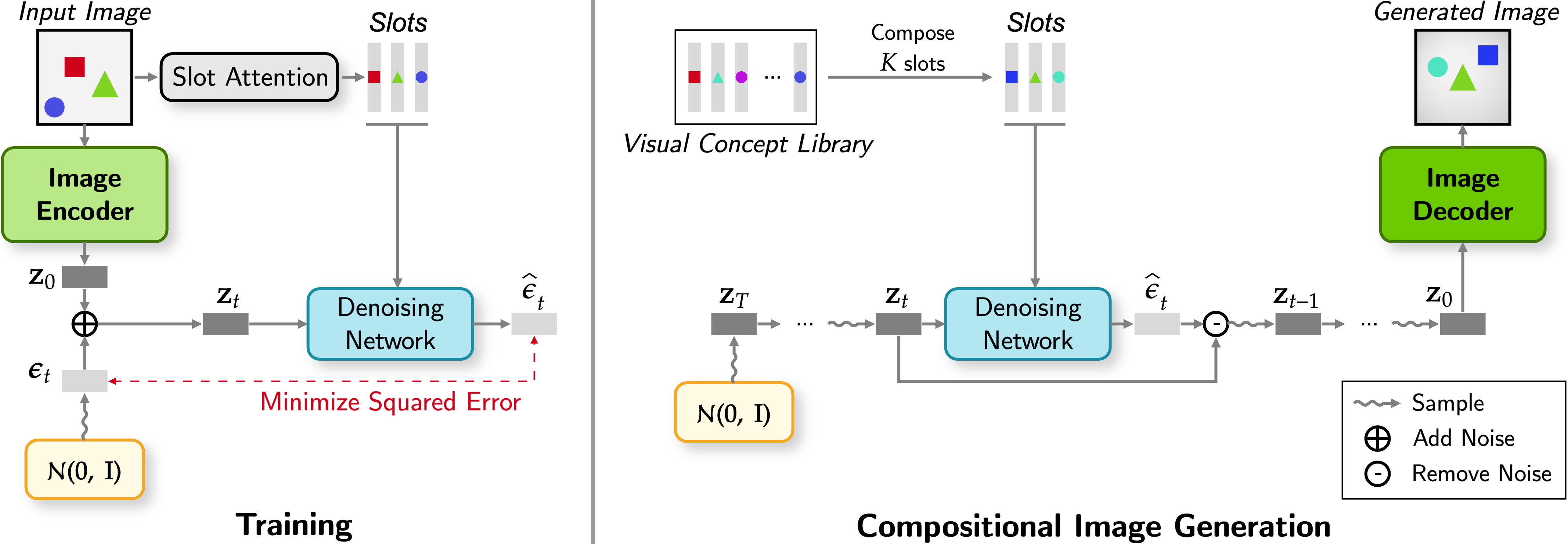
The recent success of transformer-based image generative models in object-centric learning highlights the importance of powerful image generators for handling complex scenes. However, despite the high expressiveness of diffusion models in image generation, their integration into object-centric learning remains largely unexplored in this domain. In this paper, we explore the feasibility and potential of integrating diffusion models into object-centric learning and investigate the pros and cons of this approach. We introduce Latent Slot Diffusion (LSD), a novel model that serves dual purposes: it is the first object-centric learning model to replace conventional slot decoders with a latent diffusion model conditioned on object slots, and it is also the first unsupervised compositional conditional diffusion model that operates without the need for supervised annotations like text. Through experiments on various object-centric tasks, including the first application of the FFHQ dataset in this field, we demonstrate that LSD significantly outperforms state-of-the-art transformer-based decoders, particularly in more complex scenes, and exhibits superior unsupervised compositional generation quality. In addition, we conduct a preliminary investigation into the integration of pre-trained diffusion models in LSD and demonstrate its effectiveness in real-world image segmentation and generation.






@inproceedings{jiang2023object,
title = {Object-Centric Slot Diffusion},
author = {Jiang, Jindong and Deng, Fei and Singh, Gautam and Ahn, Sungjin},
booktitle = {Advances in Neural Information Processing Systems},
volume = {36},
pages = {8563--8601},
url = {https://proceedings.neurips.cc/paper_files/paper/2023/file/1b3ceb8a495a63ced4a48f8429ccdcd8-Paper-Conference.pdf},
year = {2023}
}